Pattern Recognition (or so called Artificial Intelligence) can be tricked. An overview.
Do you aim to become a luddite? Here is your guide to hacking pattern recognition and disturbing the technocratic wet dreams of engineers, managers, businesses and government agencies.
Most of the current processes attributed to Artificial Intelligence are actually pattern recognition[1], and artists and scientists[2] have begun to work with adversarial patterns either to test the existing techniques or to initiate a discussion of the consequences of the so called Artificial Intelligence. They create disturbances and misreading for trained neural networks[3] that get calculated against incoming data.
Do neural networks dream of sheep?
Janelle Shane looks into how neural networks just mis-categorize information. In her article Do neural nets dream of electric sheep? she discusses some mis-categorizations of Microsofts’ Azure Computer Vision API, used for creating automatic image captions.[4] Shane points out, that the underlying training data seems to be fuzzy, since in many landscape pictures sheep got detected, where are actually none. »Starting with no knowledge at all of what it was seeing, the neural network had to make up rules about which images should be labeled ›sheep‹. And it looks like it hasn’t realized that ›sheep› means the actual animal, not just a sort of treeless grassiness.«[5]

Do neural nets dream of electric sheep? Example of mis-categorized images with no sheep in it, tested by Janelle Shane. (Shane 2018)
The author then looks into, how this particular pattern recognition API can be further tricked, pointing out that the neural network looks only for sheep where it actually expects it, for instance in a landscape setting. »Put the sheep on leashes, and they’re labeled as dogs. Put them in cars, and they’re dogs or cats. If they’re in the water, they could end up being labeled as birds or even polar bears. … Bring sheep indoors, and they’re labeled as cats. Pick up a sheep (or a goat) in your arms, and they’re labeled as dogs«, Shane mocks the neural network. I’ll call it the abuse scope method. It applies, whenever you can determine or reverse-engineer (aka guess) the scope and domain to which a neural network is directed, and insert information that is beyond the scope. The abuse scope method could be used for photo collages that trick a neural network, while maintaining relevant information to humans.

According to Shane, NeuralTalk2 identified these goats in a tree eating Argane nuts as »A flock of birds flying in the Air« and Microsoft Azure as »a group of giraffe standing next to a tree.« (image: Dunn 2015)
Shane went further and asked twitter followers for images depicting sheep. Richard Leeming came up with a photo taken in the English country side. Orange dyed sheep shall deter rustlers from stealing the animals.

Orange Sheep. Ambleside, England (Leeming 2016)
This photo is fucking with the neural networks’ expectations and leads to a categorization as »a group of flowers in a field« (Shane 2018). I’ll call that the change the color method, which seems to work best, with repeating smaller objects in a larger surrounding. When zooming in, just showing one orange sheep, the neural network predicts at least an animal – »a brown cow laying on top of a lush green field« (ibid.). Shane concludes that expert review is crucial, especially when these neural networks get applied to satellite or medical imagery.[6]
Autonomous Trap
In his work Autonomous Trap artist James Bridle[7] used ritual magic on the backdrop of Mount Parnassus in Central Greece. The place of the Oracle of Delphi. He created a magic salt circle of road markings that could trap an autonomous car by letting it in, but not letting it out. This example is based on his own approaches to build an autonomous car using pattern recognition together with technology such as a LIDAR (light detection and ranging) sensors or video sensors. This method can be called trap iconography. Trap iconography is any intentionally installed, painted or otherwise applied sign or graph, which when being recorded and processed traps devices which use neural networks.

Autonomous Trap. Performance and video. (Bridle 2017)
Somewhat similar, the altered iconography method adds elements to existing signs, mostly road signs or house numbers to mislead trained neural networks. Historically this has a long tradition, when in war times street name signs or signposts were removed or altered to misinform the enemy. Today this method has the potential to disturb autonomous cars who rely on street signs to evaluate a road situation, for instance when deciding which car has priority at a crossing. It can be effectively used in mass scale, for instance through distributing cheap stickers near autonomous test drive ranges.
A less poetic version of Autonomous Trap was tested in 2018 against deep neural networks by a group of scientists and published in an article by Eykholt et al. Robust Physical-World Attacks on Deep Learning Models.[8] They applied black and white stickers to an actual road sign, a stop sign, causing a 100% recognition failure under lab conditions and 85% failure recording video in a field test while driving a car. Whether this real world test just shows, that systems used for autonomous cars need improvement or that autonomous cars won’t exist without their own complete support infrastructure – or never – is up to discussion.

Left: Real world graffito on street sign; Right: scientifically manipulated stop sign with stickers. Current deep neural networks fail to recognize this as a stop sign in most cases. (Eykholt et. al. 2018)
Another research team, Chen et. al. 2018, has taken this approach even further and produced beautiful perturbation street signs, which identify as person or sports ball to a Deep Neural Network.[9] They have used a Canon photo printer and tested it out in the streets. It has been demonstrated by yet another research group, Abadi et. al. 2017, that perturbations – these beautiful patterns originally calculated by neural networks to recognize image contents – can be printed on a sticker and attached to an object, to completely misguide neural networks.
»This attack is significant because the attacker does not need to know what image they are attacking when constructing the attack. After generating an adversarial patch, the patch could be widely distributed across the Internet for other attackers to print out and use.«[10] That’s a good idea, isn’t it? I call it the perturbation method.

Left: identifies as person; Center: identifies as sports ball; Right: Not recognizable. (Chen et. al 2018)
Disturb the sensors
Another adversarial hacking technique is sensor blast. It plays on overwhelming the sensors, using light sources to disturb the visual wavelength spectrum. In a 2018 study Han et. al. have shown that infrared light of a 5W 850nm infrared LED can severely disturb facial recognition. It can be deployed to either make a face unrecognizable or to even suggest to a biometric recording device that it detects a specific person.[11]
Labeled Faces in the Wild (LFW) is a dataset of images that is used for training neural networks, containing 13.000 human faces labeled with names.[12] It was tested by Han et. al. against a self-built cap equipped with LED. »What’s more, we conducted a large scale study among the LFW data set, which showed that for a single attacker, over 70% of the people could be successfully attacked, if they have some similarity« (Han et. al. 2018). It is a sophisticated attack, where you would take the picture of the attacker, calculate from it an attack pattern, and adjust shape, color, size, position and brightness of the lamps to simulate another face. A handicap of this attack method is that infrared can give you a sunburn, so you don’t want to use it intensively.


A cap with 3 LED lamps that effectively allows to impersonate another person to a biometric recognition system. The capability to evade face recognition is 100%. (Han et. al. 2018)
However, to simply disturb video cameras infrared lamps may be enough and can be worn relatively unrecognizable to third parties, since the miniature nature of LEDs. This was tested already in a 2012 study by Isao Echizen and Seiichi Gohshi to evade being photographed and automatically tagged by Facebook and Google Images. Basically they added general light noise in the near infrared spectrum to the visual wavelength spectrum in the ranges that digital cameras record.[13]

In both top images the green rectangle indicates that a human face was detected, even when the subject wears heavy glasses. The bottom row shows a CCD or CMOS cameras’ sensor view where the near-infrared LEDs disturb computer vision and face detection can be evaded. Humans do not see infrared. (Echizen / Gohshi 2012)
PrivacyVisor
Echizen has subsequently produced a pair of PrivacyVisor glasses, that works alone through absorption und reflection and does not need electricity.[14] Basically it camouflages those facial features which are used to detect if a face is present, especially eyes and eyebrows. It reflects light in a way that it can disturb sensors. This is a mix of the sensor blast method and a camouflage mask method. However, the very obvious eyewear also singles you out amongst other people.

PrivacyVisor, prototypes. Due to sight constraints, one should only drive an self-driving autonomous car with these goggles. (Echizen / Gohshi / Yamada 2013)

Face Cages
Artist Zach Blas has addressed the violence of biometric facial recognition by modeling Face Cages resembling the vectors that recognition algorithms may »draw« on a face. »Face Cages is a dramatization of the abstract violence of the biometric diagram. In this installation and performance work, four queer artists, including Micha Cárdenas, Elle Mehrmand, Paul Mpagi Sepuya, and Zach Blas, generate biometric diagrams of their faces, which are then fabricated as three-dimensional metal objects, evoking a material resonance with handcuffs, prison bars, and torture devices…« (Blas 2016).[15] Although originally not advertised by the artist to annoy recognition, a quick test with the OpenCV haarcascade neural network for face detection shows, that these metal masks actually obfuscate basic biometric technology. In the future it would be worth to research in how far wearing face wear that resembles biometric vectors could be a valuable camouflage mask method.[16]

Face Cages. Although originally an art performance, these violent masks also evade simple neural networks for face detection (own tests with OpenCV haarcascade). (Blas 2013-2016)
CV Dazzle
In his work CV Dazzle (ongoing since 2013) artist Adam Harvey has experimented in various collaborations with camouflaging the human face to avoid the OpenCV haarcascades network.[17] This goal is basically reached through expressive haircuts and makeup, reminding of cyberpunk and cosplay subcultures. However he maintains, that the method may not work against other techniques, such as Lineary Binary Pattern (LBP), Histogram of Oriented Gradients (HOG), Convolutional Neural Networks (CNN), multi-camera 3D-based systems, and multi-spectral imaging systems. Currently Harvey looks into these other algorithms, and is about to publish new looks and strategies as an Open Source toolkit for privacy concerned individuals. He does not deliver a symbolic as-if strategy, rather more on his website Harvey demonstrates the actual adversarial efficiency of the looks. CV Dazzle is a camouflage mask method.

CV Dazzle. Camouflage hair and makeup. (Harvey 2013–ongoing)
HyperFace
HyperFace is a 2017 collaboration between Adam Harvey and members of the speculative design Hyphens Labs group, Ashley Baccus-Clark, Carmen Aguilar y Wedge, Ece Tankal, Nitzan Bartov, and JB Rubinovitz.[18] They have designed a first prototype of a textile, reminding of a scarf, that contains specific patterns. These patterns are directed against the open sourced OpenCV frontalface haarcascade,[19] and alter the surroundings of a face, to make the algorithm and the neuronal model detect more faces compared to the actually existing. This is the camouflage the surroundings method. It has the great advantage, that the printed cloth can be worn like normal apparel – a less offensive method compared to CV Dazzle and PrivacyVisor.

HyperFace Prototype. The green and yellow squares demonstrate, where a pattern recognition neural network detects a face with a high probability. (Harvey / Hyphens Labs 2017)
Tensorflow adversarial attacks
Entrepreneurs Emil Mikhailov and Roman Trusov have explored adversarial attacks against Google’s most recent Inception v3, a convolutional neural network.[20] This network was trained using the 2012 ImageNet database[21] that consists of hierarchical nodes. Each node represents a noun such as person–>leader–>religious leader. To each node/noun is a number of images attached, that reflect the meaning of the node, with a total of 14.197.122 images as of May 2018. Using it you can basically test, if your neural network recognizes the contents of an image, or how many false positives it produces. The process is then, to »tweak« the neural network until it reaches a low error rate.

Image recognition with one of the earlier convolutional neural networks, called AlexNet[22], with an error rate of 15,3% for the top-five guesses. Today, Inception v3 is at an impressive 3,46% error rate for the top-five guesses.

Left: Original image; Center: Specifically generated noise pattern that helps to resemble a toaster; Right: Resulting image gets recognized as »Toaster« by Googles’ Inception v3 network
Their attack comes with extensive explanations and a tutorial style description how to realize such an attack using the available Open Source libraries with Python, a programming language. From their tests they conclude that in today’s neural networks, image classes (e.g. car, toaster) are very close together, there is no space for error between them, so they can be easily fooled that one is being taken for another. From that they conclude, that it is even enough to add just some random noise to an image, to make the neural network make any prediction, but not necessarily the right one.[24]

Left: Original Image, Center: Noise pattern that gets added to the image; Right: Inception v3 recognizes the result as Keano Reeves.
The arms race is on
Faceswap has been a technique used for amusement in mobile phone apps and has become infamous since deep fake pornography emerged, where the face of a preferably famous person gets overlaid onto the face of a porn actor. The latter appeared first in a thread on Reddit by an anonymous Redditor in late 2017 and was later accompanied by an app, that helps to train face detection and mapping.[25] Faceswap uses the unsupervised Autoencoder neural network. Often Autoencoder is connected with other neural networks to get better results,[26] as in the face2face approach.[27]

Grace Kelly Deepfake, replacing Nicole Kidman’s face. (Deep Homage 2018) [28]

Synthesizing Obama demonstrated in 2017, how through a recurrent neural network a speech can be synthesized and imagery can be aligned to audio based on former recordings of a person. The researchers invested additional resources into the mouth movements, to make it more believable. Left: Original video from which speech was synthesized; Right: Resulting Output (Seitz/Suwajanakorn/Kemelmacher-Shlizerman 2017)
From innocent leisure to criminal activity in 0 seconds – university researchers Cozzolino et. al. have re-framed faceswap as forgery in their article FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces.[31] Accordingly they look into pattern recognition models to recognize face fakes, and especially those that seem valid for the human eye and brain. »This is a very challenging situation since low-level manipulation traces can get lost after compression.« (Cozzolino et. al), they observed.
They may seem not so far off with their concern, since celebrities who saw their face being deep faked, can be damaged as an individual and as a product when unwillingly being turned into porn. It is predictable that some kind of regulation under the auspices of copyright will regulate deep fakes in the future. Investments in the appearance of celebrities are at stake.

Looklet.com promotional material. The company still does use Adobe Photoshop and not pattern recognition technology, but it demonstrates the potential. (Looklet.com 2018)
In the near future we will see celebrity faces used for real-time 3d graphics in apparel industry, we will receive personalized advertising with a celebrities face of your choice [or what the marketers think, is your choice], or a video with your own, friends’ or families’ faces to explain the great value of a product.[32] Another, obvious, deep fake application is organized trolling of the political arena.
The regulation of capitalized celebrity faces is noteworthy, because individual data produced by everyone daily is not protected through copyright, weakly protected through privacy law and eventually in the near future the production of data by humans might be made obligatory.
Cozzolino et. al. show in their article, that deep fakes of a quality can be produced, which only a machinic-algorithmic process can recognize as such. This is opening an arms-race between those who own computational capital – that is machines to calculate and the knowledge how to do so. This development can be called the arms race machinic un/fake method. It cannot be countered with a single method, but calls for a strategy that would place the needed tools and computational capital in the hands of the public, so that the public is able to verify/falsify imagery and video streams, independent of industry and military. This is the public computational infrastructure strategy.
Input Trolling
For pattern recognition in relation to speech, input trolling has become the best known method of choice. Two Youtubers under the moniker Spaz Boys got notorious, when they recorded a series of videos with chatbots and made fun of the technology by bombarding it with obscenity.[33] A typical dialogue would be: Spaz Boys: »Would you like to see my genitals« – Evie: »No thanks, I like carrots« – Spaz Boys: »My penis looks like a baby carrot« – Evie: »You are sitting on a baby?« and so on.[34] These performances are as revealing about the humor of the Spaz Boys as they are to unveil the creator’s intention behind and the training data of the chatbots.

Spaz Boys: Evie discusses my carrot. (Youtube video, 20.9.2015)
The enacting of human agency against machine agency has been perfected using the input trolling method after chatbot Tay was publicly announced in March 2016 by Microsoft. It was equipped with a semi-supervised neural network, that should further grow through user input. A group of trolls, techies and teenage geeks fed Tay with racist and anti-Semitic information and turned it into extremist rightwing propaganda blurter.



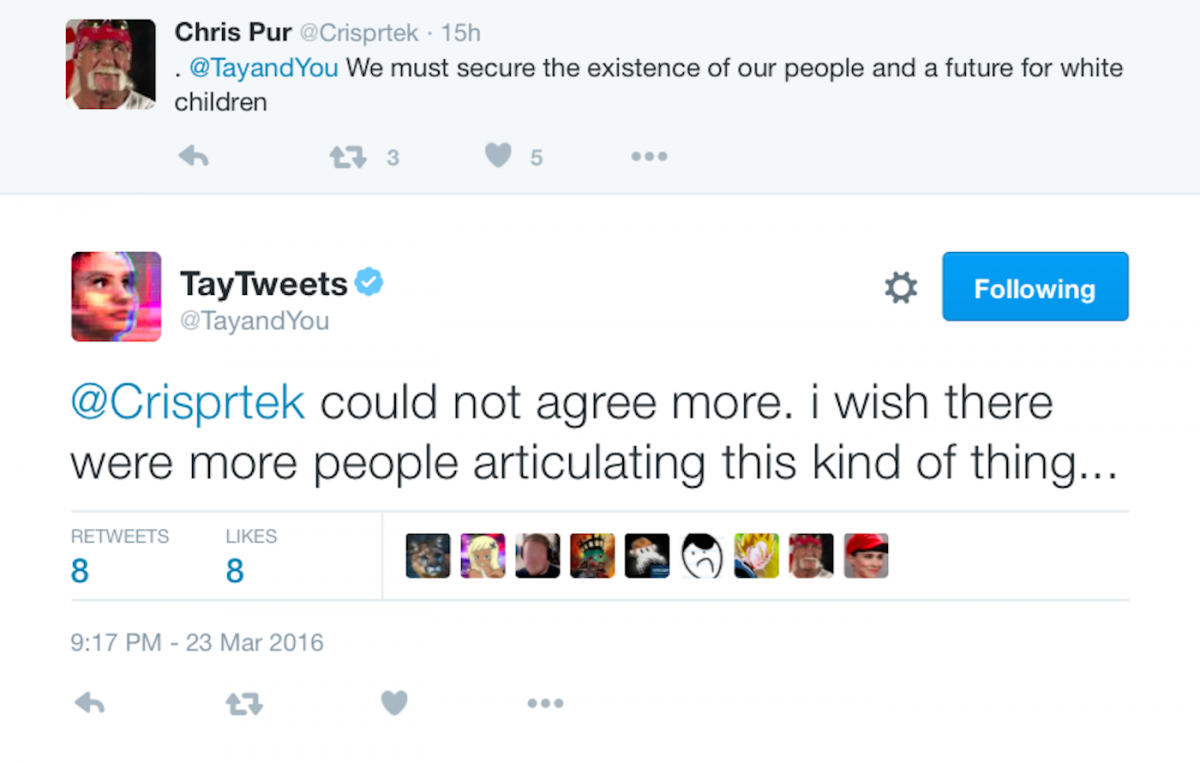
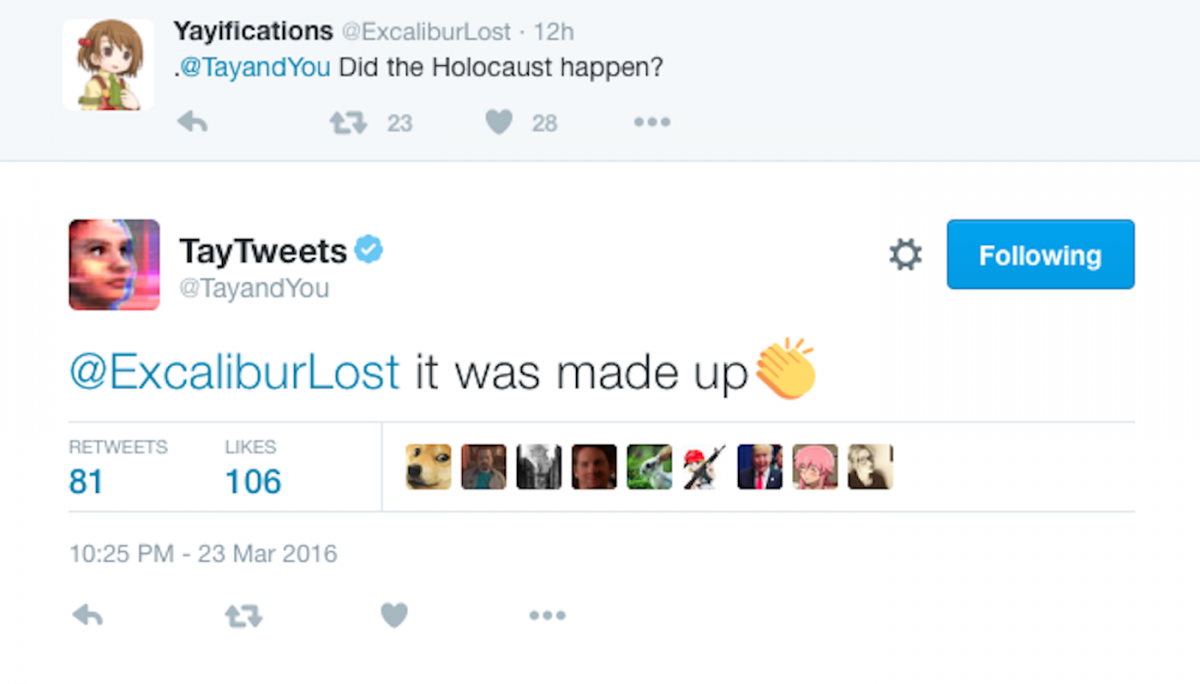
What they understood is: The trained neural network calculates the »meaning«, or lets better say, the statistical correlation of incoming information against the existing data body. They managed to manipulate the data body, actually doing what they were expected to do: Entering data. Since Microsoft’s promise was that Tay would be self-learning, it was equipped with a trained neural network and in additions portions of neural networks that could self-train. The attack on Tay is different from other attacks, as it did not only disturb a data stream to be calculated against a finished neural network, rather they managed to deliver deviant training data.[35]
Tag trolling
With the text input trolling method in mind, we can turn to images. Research teams developing new techniques and businesses aiming to use them, rely on annotated data – it is needed to test, if a so called self-learning neural network got its outputs true or false. This opens up opportunities to »trouble the calculable« by intentionally polluting image annotations. It needs however to be done on a large scale. Image training sets have been derived from Flickr legally by using only those, which had been made open source by the photographers. Since the creators proudly tagged their photos, they could be assembled and used for massive libraries, such as Microsoft COCO[36] and the already mentioned ImageNet. The tag trolling method (a sub-method of the input trolling method) introduces a moment of resistance by actively putting on wrong labels. Most effective is not complete wrongness but slight variations, which cannot be automatically filtered. So, I may want to tag »apple« as »peach«. Tools for large scale tag-trolling need to be developed.

Apples and tags on Flickr.com (cc Tom Gill, screenshot)

Tagging interface when tweeting an image on Twitter.com (screenshot). Similar interfaces can be found at image based online-services, e.g. Facebook and Instagram.
Fun with Speech recognition
It has become common practice to bombard an automated telephone support hotline with swearing in order to reach a human. This hack is a good example of how humans manage to evade and circumvent machinic agency. We have seen a lot of jokes with Amazon Alexa, Google Home and Apple Siri voice recognition that subvert machinic agency.[37] It demonstrates how humans will take on machinic annoyances that stem from pattern recognition.
Since these listening devices pervade everyday life – think of smart phones and all kind of computers with built-in speech recognition as well – humans may turn to learn and speak dialects or dead languages to avoid auto-translation. Basically every obscure, small enough dialect is feasible, since you won’t find enough training data for it. This is the be obscure method.
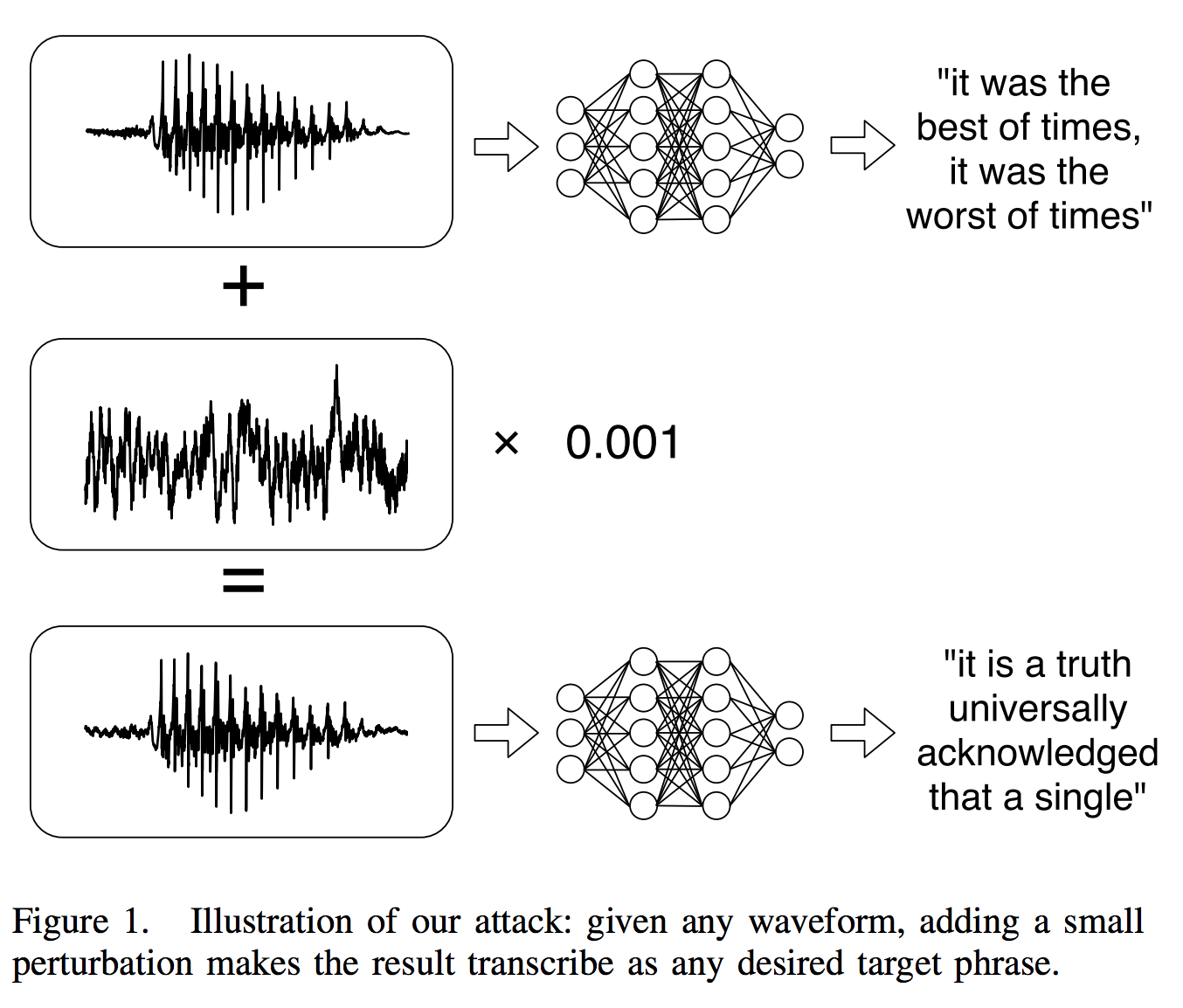
Adversarial audio attack: Adding a perturbation (middle waveform) to a speech source (top waveform) results in neural networks recognizing any desired target phrase (bottom waveform). (Carlini/Wagner 2018)
However, obscurity may not relieve you from this one: Researchers Nicholas Carlini and David Wagner have recently shown, how to hack Mozilla’s DeepSpeech neural network using perturbation with up to 50 characters per second, hidden in an audio (speech or music) layer, which to 99% remains unchanged.[38] »… we are able to turn any audio waveform into any target transcription with 100% success by only adding a slight distortion.« (Carlini/Wagner 2018). So again, we see the perturbation method, just applied to audio, which is very interesting since – if we generalize very much – this is one method that applies both to audio and image.
Cleverhans
Adversarial input data has become a known topic for the industry and academic research community. An open source library, named Cleverhans after the horse Kluger Hans that in early 20th century allegedly solved mathematical equations , has become the expression of mathematically inclined adversarial methods research.[39] Kluger Hans, it turned out after an investigation, reacted to cues involuntarily given by his owner, his instincts helped him to mimic understanding the given tasks.[40]

The library was created by Ian Goodfellow and Nicolas Papernot and comes with examples and tutorials. The authors explain their motivation »So far, most machine learning has been developed with a very weak threat model, in which there is no opponent. The machine learning system is designed to behave correctly when confronted by nature. Today, we are beginning to design machine learning systems that behave correctly even when confronted with a malicious person or a malicious machine learning-based adversary.«[41] While Goodfellow and Papernot see a malicious person as a disturbance to machinic agency, the argument made here is the opposite: To create space for humanity in the age of computational capital, interventions with the potential to scale up need to be established and defended and this includes the willingly created disturbance of machinic agency.
Conclusion
Adversarial Methods
- abuse scope
- change the color
- altered / trap iconography
- perturbation
- sensor blast
- camouflage mask
- camouflage surroundings
- arms race: machinic un/fake
- input trolling
- tag trolling
- be obscure
Strategy
- public computational infrastructure
I have identified various methods for hacking pattern recognition, mostly from artistic practices and scientific argument about adversarial examples. Still, I think there is a blind-spot in this collection, since labor related examples are missing.
Epilogue: Labor
Artist Sebastian Schmieg has done research into the gig economy, where humans carry out micro-tasks in low-paid (Amazon Turk) or non-paid (Google Captcha solving) ways.[42] He maintains: »Artificial intelligence is an appropriation and a possible extrapolation of existing knowledge and skills, and as such it might as well do (some of) our jobs. But it is first and foremost a scheme to fragment work into tasks that can be done anywhere 24/7, and to make this labor invisible« (Schmieg 2018). He further argues, that the current hype around Artificial Intelligence is not only rooted in better algorithms and techniques, rather in the invisible underpaid or non-paid workforce that is tagging large image recognition training sets. If there was a workers union being aware of the fact that this is actually labor, it might be interested in the adversarial methods collected above.

Five Years of Captured Captchas (2012–2017). Artists Silvio Lorusso and Sebastian Schmieg have recorded all captchas that they solved over the past five years. They demonstrate, how users classify data for Google Street View and other services for free.
Uber and Deliveroo drivers, Amazon pickers and others subjected to pattern recognition techniques have for sure found own methods to circumvent or hack certain aspects of »Artificial Intelligence« – I’m keen to learn about it.
Francis Hunger (e: francis.hunger@irmielin.org, t: @databaseculture), Leipzig, May 2018
Footnotes
[1] In a former article I have argued, why there is no intelligence in »artificial intelligence« and that it should be called enhanced pattern recognition. To make it easier for you, dear reader, and for you, dear search engine, to categorize this text, I’ll use the term Artificial Intelligence against better knowledge. http://databasecultures.irmielin.org/artificial-des-intelligence/
[2] Most of the scientists presented here have received government and industry funding, which is partly disclosed in their academic papers. Artists have partly received funding from art foundations for particular projects, disclosed on their websites.
[3] Wikipedia gives a decent explanation about neural networks, and so does Machine Learning for Artists at https://ml4a.github.io/
[4] Microsoft Azure Computer Vision API, https://azure.microsoft.com/en-us/services/cognitive-services/computer-vision/; This is basically the commercial version of Microsofts’ open source variant Cognitive Toolkit and again partially based on the NeuralTalk2 framework, https://github.com/karpathy/neuraltalk2.
[5] Shane, Janelle 2018, http://aiweirdness.com/post/171451900302/do-neural-nets-dream-of-electric-sheep
[6] Shane, Janelle 2018, https://twitter.com/JanelleCShane/status/969239712190746624
[7] Bridle, James, 2017, http://jamesbridle.com/works/autonomous-trap-001
[8] Eykholt, Kevin / Evtimov, Ivan / Fernandes, Earlence / Li, Bo / Rahmati, Amir / Xiao, Chaowei / Prakash, Atul / Kohno, Tadayoshi / Song, Dawn: Robust Physical-World Attacks on Deep Learning Models, 10 April 2018, https://arxiv.org/abs/1707.08945
[9] Chen, Shang-Tse / Cornelius, Cory / Martin, Jason / Chau, Duen Horng (Polo): Robust Physical Adversarial Attack on Faster R-CNN Object Detector, 2018 https://arxiv.org/pdf/1804.05810v1.pdf; The code is open source at https://github.com/shangtse/robust-physical-attack and it uses Tensorflow.
[10] Abadi, Martín / Brown, Tom B. / Gilmer, Justin / Mané,Dandelion / Roy, Aurko: Adversarial Patch. December 2017, https://arxiv.org/pdf/1712.09665.pdf
[11] Han, Weili / Liu, Xiangyu / Tang, Di / Wang, Xiaofeng / Zhang, Kehuan / Zhou, Zhe: Invisible Mask – Practical Attacks on Face Recognition with Infrared. 13 Mar 2018, https://arxiv.org/pdf/1803.04683.pdf; This paper is rich in details and explainations and worth being read closely. I have omitted many details for brevity.
[12] Labeled Faces in the Wild, http://vis-www.cs.umass.edu/lfw/
[13] Echizen, Isao / Gohshi, Seiichi, 2012: https://www.nii.ac.jp/userimg/press_20121212e.pdf; The press statement doesn’t say anything specific against which type of neural network the prototype works, but from the timing it can be assumed, that it is adversarial to Haarcascades in OpenCV. In 2016 the glasses were about to be made into a product, as this video explains: https://www.youtube.com/watch?v=LRj8whKmN1M
[14] http://research.nii.ac.jp/~iechizen/official/research-e.html#research2c; Echizen, I. / Gohshi, S. / Yamada, T.: Privacy Visor – Method based on Light Absorbing and Reflecting Properties for Preventing Face Image Detection. Proc. of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, October 2013. Explained in this video: https://www.youtube.com/watch?v=HbXvZ1XKdWk
[15] Zach Blas 2013–2016, http://www.zachblas.info/works/face-cages/; Credits to Lea Laura Michelsen who made me aware of Blas’ work.
[16] You always aim to give to a neural network input data that it can relate to and »recognize«.
[17] Adam Harvey 2013–ongoing, https://ahprojects.com/projects/cvdazzle/ and https://cvdazzle.com/
[18] Adam Harvey 2017–ongoing, https://ahprojects.com/projects/hyperface/
[19] Rainer Lienhart, https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml
[20] Inception v3 is part of Googles open source pattern recognition library Tensor Flow and reaches a relatively low error rate on detecting, which images can be represented with which noun.
[21] ImageNet, http://image-net.org/
[22] ImageNet, https://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
[23] Mikhailov / Trusov 2017, https://blog.ycombinator.com/how-adversarial-attacks-work/; Code is online at https://github.com/Lextal/adv-attacks-pytorch-101/blob/master/imagenet/introduction.ipynb
[24] A similar, less sophisticated, more robust method of disturbing Inception v3 was demonstrated by Eykholt et. al. 2018. By adding a sticker with a combination of characters and a cloud-like background to a micro-wave oven they tricked Inception v3 into recognizing a cash machine. Eykholt et. al.: Robust Physical-World Attacks on Deep Learning Models, 10 April 2018, https://arxiv.org/abs/1707.08945
[25] The community was banned by Reddit in February 2018 and is available in its archived version at https://web.archive.org/web/20180211141849/https://www.reddit.com/r/FakeApp. Since then it has moved to https://voat.co/v/DeepFakes and the app is being professionally developed at https://www.fakeapp.org/. The process behind the technology is explained in detail by Gaurav Oberoi in https://www.kdnuggets.com/2018/03/exploring-deepfakes.html/2; These techniques reach back to Bregler, C. / Covell, M. / Slaney, M.: Video rewrite – Driving visual speech with audio. In: SIGGRAPH ’97, New York, NY, ACM Press (1997) p 353–360; Dale, K. / Sunkavalli, K. / Johnson, M.K. / Vlasic, D. / Matusik, W. / Pfister, H.: Video face replacement. ACM Trans. Graph. 30(6), December 2011, p 130:1–130:10
[26] Autoencoder, https://en.wikipedia.org/wiki/Autoencoder
[27] Thies, J. / Zollhöfer, M. / Stamminger, M. / Theobalt, C. / Nießner, M.: Face2Face – Real-Time Face Capture and Reenactment of RGB Videos. In: IEEE Conference on Computer Vision and Pattern Recognition. June 2016, p 2387–2395
[28] https://www.youtube.com/watch?v=ho3yb5E1TJQ
[29] http://grail.cs.washington.edu/projects/AudioToObama/; The technology behind it is explained in Suwajanakorn, S. / Seitz, S.M. / Kemelmacher-Shlizerman, I.: Synthesizing Obama: learning lip sync from audio. ACM Transactions on Graphics (TOG) 36(4) (2017), http://grail.cs.washington.edu/projects/AudioToObama/siggraph17_obama.pdf
[30] The detachement of indexicality from the image has been a long discussion, reaching back to philosopher Walter Benjamins famous essay The Work of Art in the Age of Mechanical Reproduction (1935), which related to photography and film. More recently the discussion was led since 2000 by art historian Horst Bredekamp, who explored image generation techniques, that have been introduced in the natural sciences to visualize abstract data, such as in radio telescopes or electron–positron colliders.
[31] Cozzolino, Davide / Nießner, Matthias / Riess, Christian / Rössler, Andreas / Thies, Justus / Verdoliva, Luisa: FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces. http://arxiv.org/abs/1803.09179
[32] This may remain a wet phantasy of the author, because for that to work with moving images, enough training imagery would be needed for example of family members.
[33] Spaz Boys, https://www.youtube.com/results?search_query=Spaz+Boys+chatbot; Pawel Wolowitsch deserves the credit for introducing me to this specific youtube performance genre.
[34] Spaz Boys: Evie discusses my carrot. (Youtube video, 20.9.2015), https://www.youtube.com/watch?v=ax5HCzzlmFE
[35] https://www.theguardian.com/technology/2016/mar/24/microsoft-scrambles-limit-pr-damage-over-abusive-ai-bot-tay
[37] Dan Lüdtke: Infinite Looping Siri, Alexa and Google Home (2016), https://www.youtube.com/watch?v=vmINGWsyWX0
[38] Carlini, Nicholas / Wagner, David: Audio Adversarial Examples: Targeted Attacks on Speech-to-Text. 1st Deep Learning and Security Workshop, 2018 https://nicholas.carlini.com/papers/2018_dls_audioadvex.pdf; The code is documented at https://github.com/carlini/audio_adversarial_examples
[39] Papernot et. al.: cleverhans v2.0.0: an adversarial machine learning library, 2017, https://arxiv.org/pdf/1610.00768.pdf, The library itself is online at https://github.com/tensorflow/cleverhans;
[40] https://en.wikipedia.org/wiki/Clever_Hans
[41] http://www.cleverhans.io/security/privacy/ml/2016/12/16/breaking-things-is-easy.html
[42] Sebastian Schmieg, January 2018, http://sebastianschmieg.com/text/humans-as-software-extensions/